

Visão Computacional
1. Representação de
imagens
2. Filtragem de imagens
3. Detecção de Bordas
4. Segmentação Simples
5. Crescimento de Regiões
6. Segmentação com
Filtros
7. Segmentação a Cores
8. Análise de Texturas
9. Análise de Texturas
Multiescalar
10. Redes Neurais
11. Morfologia Matemática
12. Convolução
13. Esqueletonização
14. Técnicas Estatísticas
15. Fractais
16. Reconhecimento de
Formas
17. Representação de
Objetos
18. Quadtrees e Octrees
19. Visão Estereo
20. Inteligência Artificial
21. Controle de qualidade
22. Robótica
23. Medicina
24. Sensoriamento remoto
Prof. Aldo von Wangenheim
Currículo...
Publicações
Pesquisa
Projetos
Ensino de Graduação
Ensino de Pós Graduação
Cursos
Incorporando um Módulo de Visão Conexionísta em um Controlador de Robô Fuzzy, Baseado em Comportamento
<Douglas S. Blank
and J. Oliver Ross>
<Artigo
Origin>
Resumo
Este artigo descreve os passos iniciais exigidos para incorporar um módulo de visão de uma rede neural artificial em uma lógica difusa estabelecida de um robô móvel baseado em comportamento e controlador. Este método eficiente e robusto é apresentado para mostrar sua efetividade em ambientes de um mundo real simples.
Introdução
Embora Zadeh tenha definido as operações básicas de teoria fixa difusa a mais de trinta anos atrás (Zadeh, 1965), controladores baseados em lógica difusa se tornaram, apenas recentemente, a técnica de escolha para muitos pesquisadores em robótica. A chave para esta linha próspera de pesquisa foi o desenvolvimento do conceito de comportamentos.

Figura1:
Robô RazorBot
Comportamentos
Comportamentos como um método de controlar robôs foram inspirados na arquitetura de assunção de Brooks (Brooks, 1986) e depois generalizado por descrições de Maes' de desígnios baseados em comportamento (Maes, 1993). Geralmente, um comportamento é uma simples associação de ativação e ação. Tem-se como exemplo: SE porta-a-esquerda ENTÃO va-para-esquerda. A porta-a-esquerda é o gatilho de perceptual que ativa o robô para va-para-esquerda.
As idéias de comportamentos e lógica difusa combinam perfeitamente; comportamentos provêem uma interface abstrata para os humanos situarem-se, e a lógica difusa provê um método para lidar com valores de variável inexatos.
Aprendizado
A meta deste trabalho é integrar um aprendizado nesta metodologia famosa. Esta aprendizagem será necessária para os robôs processar informações mais complexa, para executarem tarefas mais complexas.
Uma maneira óbvia de incorporar aprendizado em um sistema de controle difuso é tentar aprender as regras de lógica difusas. Porém, os humanos são eficazmente e efetivamente capazes de trabalhar com regras abstratas, como SE obstáculo-a-direito ENTÃO va-para-esquerda.
Embora obstáculo-a-direita possa ser um sinal de baixo nível percebido facilmente, sinais mais sofisticados não podem. Por exemplo, considere tentar aproximar-se de cachorros, mas evitar gatos. O módulo humano no controlador pode criar as regras facilmente (i.e., SE gato ENTÃO motores-contrários). A dificuldade está em propor valores de verdade apropriados para a categoria de gato e de cachorro.
Uma solução
para este problema é inserir uma rede neural artificial entre os
sensor de baixo nível e o controlador de lógica difusa. Podem
ser treinadas redes neurais artificiais (por backpropagation ou algum outro
método) usando as leituras dos sensores de baixo nível, e
produzindo valores de ativação. Uma rede pode ser treinada
para ler em imagens 2D e leituras de sonar, produzindo uma representam
da presença ou ausência de um gato. O valor de produzido é
tratado como um valor de probabilidade no controlador de lógica
difusa.
Módulo de Visão Conexionista
A tarefa especifica era reconhecer uma bola em movimento e ajudar o RazorBot parar a bola. Depois de algumas experimentações, foi decidido manter a resolução visual tão pequena quanto possível, mas com informações suficientes para o reconhecimento de objeto. Uma imagem 44 x 48 pixels, com três cores por pixel (RGB) foi suficiente.
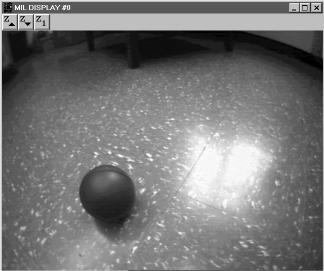
Figura 2: Imagem capturada.
Foi decidido por uma categorização simples de qual quadrante se encontra a boa. Foram criadas quatro unidades, uma para cada quadrante. Para algoritmo de treinamento foi escolhido o backpropagation.
Foram capturadas 100 imagens
da visão do robô, treinou-se com 90 imagens e usou-se 10 para
testar habilidade de generalização. Cada um dos 6336 pixels
foi arredondando para 0 e 1, para que a pudesse aprender a tarefa. A rede
contém 10 neurônios na camada escondida.
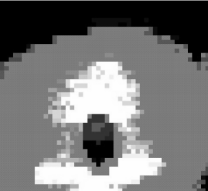
Figura 3: Imagem vista
pelo RoazorBot.
Integração
Para integrar o Saphira e o módulo de visão de conexionísta foi necessário um método para criar variáveis difusas que poderiam ser usadas para controlar os motores do RazorBot. Foi decidido criar uma variável difusa para cada quadrante. Cada variável indicaria a estimativa da rede da probabilidade da bola estar naquele quadrante.
Sendo q1 a ativação da unidade que representa a presença de uma bola no quadrante 1. Então, a pessoa pode escrever comportamentos da seguinte forma:
SE (q1 OU q3) ENTÃO
Ir para a Esquerda
SE (q2 OU q4) ENTÃO
Ir para a Direita
onde q1 e q3 são os quadrantes no lado esquerdo da imagem visual. Os valores de saída da rede tem a vantagem de ser fácil calculados. Porém, as ativações de produção não necessariamente correspondem a valores de probabilidade. Então foi necessário normalizar os valores de saída antes de usá-las no Saphira.
Conclusões
Os resultados iniciais são promissores, porém, falta comparar esta metodologia com outras técnicas.
Embora a rede categorizou corretamente 80% das imagens no teste de generalização, acredita-se que com um treinamento mais rico ajudaria na generalização, como também criando valores de saída que não precisariam de ser normalizado.
Atualmente, a imagem visual
é provavelmente pobre demais. A 44 x 48, a resolução
está nos limites para reconhecimento de bola plano. Tarefas de reconhecimento
mais complexas podem requerer uma resolução melhor. Porém,
o máximo que se conseguiu para cada cor RGB foi arredondado fora
para 0 ou 1.
Contato:
Tel.: +55-48-331 7552/9498 |
 |

